
论文译文
外文原文题目:ArrayFire: a GPU acceleration platform
中文译文题目:ArrayFier:一种GPU加速平台
原文作者:James Malcolm, Pavan Yalamanchili, Chris McClana- han, Vishwanath Venugopalakrishnan, Krunal Patel, 和 John Melonakos
所属单位:Emory University、Gujarat Power Engineering and Research Institute、ArrayFire等
译文作者:岳昕阳
所属单位:重庆劳格科技有限公司
原文发表于:researchgate网站
https://www.researchgate.net/publication/258716823_ArrayFire_a_GPU_acceleration_platform
版权所有 非授权谢绝转载
摘要
ArrayFire是一个可以利用C、C++、Fortran和Python语言实现通用型GPU(general purpose GPU,GPGPU)计算应用程序的快速软件开发的GPU矩阵库。ArrayFire包含一个简单的应用程序编程接口(API)并且为CUDA框架和支持OpenCL的设备提供完整的GPU计算能力。它同样还可以提供数千种GPU调谐功能,包括线性代数、卷积、约减与快速傅立叶变换(FFTs),同时还提供信号、复数、统计学与制图学库。我们将进一步描述ArrayFire是如何支持GPU计算应用程序的开发的并且将着重介绍其中一些关键功能在实际代码操作中如何实现。
关键词:CUDA,GPU,GPGPU,ArrayFire,OpenCL
1.介绍
ArrayFire是一个搭建在AccelerEyes网站上的软件平台,它可以为使用者和编程人员提供C、C++、Fortran和Python语言的快速并行数据程序开发,并且在低级GPU应用程序编程接口(例如CUDA、OpenCL和OpenGL)上提供一种简单的高级矩阵抽象,再加上利用数千种GPU调谐组件,可以为使用者在科学、工程、金融等方面保持GPU硬件的完整优势。由于同时拥有使用简单的阵列界面、自动内存管理功能、程序运行中编译功能、用于构造环的并GPU和交互式硬件加速图像库,ArrayFire可以很好的完成并行数据算法的快速原型设计任务与构建已经部署的应用程序任务。
过去十年间,消费者和计算机开发人员对GPU的需求快速上升,尽管成功案例越来越多,GPU软件被开发出来后被采用的数量却只有缓慢的提升。采用量提升缓慢的原因主要是GUP编程较为困难
Cg、GLSH、HLSL和Brook语言的出现标志着流编程开始出现,而流编程语言又是通用型GPU编程的前身,而通用型GPU会将运算映射到图像管道进而导致收到各种限制。随着这些技术的发展,CUDA和OpenCL介绍了一种更加综合性的可编程软件结构,这种结构比流编程更简单,但是也比标准的单线程C/C++更难编程。然而,就算是新的可编程软件结构有这么多优点,绝大多数编程人员依然需要花费大量的时间学习CUDA、OpenCL等新语言才能完成一次成功的编程。
有几家私人企业同样打算达到这些目的。首批这样的公司之一,PeakStream创建了一个C/C++的运行时间和提供大量GPU构造工具集的函数库。RapidMinds公司创建了一个灵活的支持多种前端语言和多种后端硬件目标的中间层。这两项尝试都打算帮助开发人员去更好的控制硬件。而ArrayFire作为最新的GPU构造平台,打算把高级功能移植到底层硬件上去,最终实现在不牺牲整体性能的情况下,提供可编程性与可移植性。
2.ARRAYFIRE
2.1语言支持:C++、Fortran、Python
ArrayFire围绕单个矩阵对象(阵列),此矩阵可以容纳浮点值(单或双精度)、实数或复数值和布尔数据。以下是一个展示如何使用矢量化ArrayFire表示法利用蒙特卡罗估计表示π的值:创建两个向量样本(x,y),并计算有多少落在单位圆的一象限内。
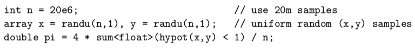 图1 使用ArrayFire利用随机取样法估算π的值
图1 使用ArrayFire利用随机取样法估算π的值
ArrayFire的阵列式是多维度的,可以通过简单的矩阵生成函数例如(ones、randu等)生成,而且可以通过算法和函数进行操纵。另外,ArrayFire提供一条并行for循环工具——gfor——可以以并行数据的形式任意执行许多独立历程。更多细节和例子已经上传到网络上。
2.2例子:立体视差
 图2 使用ArrayFire通过平面扫面和5-by-5相关窗口计算两个图像之间的水平差距。所有视差计算和最终最小值都是并行执行的,而且执行时保证源代码是简单且不被更改的,不需要深入到低级GPU的应用程序接口中。
图2 使用ArrayFire通过平面扫面和5-by-5相关窗口计算两个图像之间的水平差距。所有视差计算和最终最小值都是并行执行的,而且执行时保证源代码是简单且不被更改的,不需要深入到低级GPU的应用程序接口中。
在上方展示的简易例子中(图2)我们展示了两张图片之间立体视差的计算方式。这段代码可以在任何支持ArrayFire的设备上运行,而且由于不需要类似于CUDA或OpenCL的低级GPU编程API而保持了简明。ArrayFire通过使用平面扫描和5-5相关窗口实现水平差计算。所有差值计算与最终最小值都是并行执行的,且源代码可以保持干净简洁而不涉及到低级GPU应用程序编程接口。
程序是被逐行的描述的,left、right和sad的声明表明我们将使用4位浮点阵列而且left和right是我们已经获得的图像。我们假定所有阵列大小相同。我们还创建了核,一个单精度5-5滑动窗口(sliding 5-by-5 window)。
第二行利用gfor关键词表示了我们将并行运算一下模块从0到nshift共nshift+1次。所有后面的指令依然只读区一次,不过每条指令都将调用nshift+1次计算而不是只调用一次。因此,下一个指令将right图片移动一个像素、两个像素、以此类推,然后将结果(如果立刻编译并执行)作为把手(handle)储存在变量shifted中。剩下的命令行将在一个5-5的滑动窗口中计算两个图片之间的绝对差值的和。最后,就得到了所有计算所得绝对差值的和的最小值。需要注意的是在执行期间,Array Fire编译指令可以惰性编译,也就是说,前面提到的所有操作可以合并成一个GPU执行批次并派发给GPU。
3.惰性编译
ArrayFire使用了一种名叫惰性编译的技术(有时也被称为及时计算,Just-In-Time computation,JIT)用于尽可能提升用户程序的运行速度。这项正在申请专利的技术在保证了灵活性的情况下既可以在运行中生成计算设备代码又可以优化内存传输以达到最大流率。
在GPU上执行运算程序最简单的方法就是在用户输入/运行代码的时候在GPU上执行每个操作。这是可行的,而且可能加快运算速度,但并不是理论上最快的。
每当ArrayFire端口连接到GPU都需要耗费一些时间。除了计算实际耗费的时间外,设备之间通讯和GPU通讯同样会消耗时间。ArrayFire将追踪用户正在进行的计算并储存公式、输入值与最终结果,当需要执行命令时,ArrayFire将直接给出结果而不是再次进行计算以此来使第二次执行的速度更快。
考虑以下代码:
 在后台程序中,ArrayFire将建立这些部分表达式,但在实际计算任何设备代码时:
在后台程序中,ArrayFire将建立这些部分表达式,但在实际计算任何设备代码时:
 在计算C之前I是否更改无关紧要,ArrayFire持续追踪输入源头,而你将总是得到正确答案。每当你需要C的值,它都将自动进行运算。由于对C的计算可以作为单个核进行批处理而不是把里面的每个式子都执行一遍,这种处理方式相对于把每一步都交给GPU处理一次来说节省了时间。ArrayFIre利用这些信息进一步优化更大图片的计算版本,否则一条一条执行操作将变得不可能。你能从其中得到的另一个优点是在你代码里运行计算了一个,你实际上永远不会使用的值时,ArrayFire可以直接跳过它。如果计算C所需要的内存开始不足或者计算过程开始变得极端复杂,ArrayFire也可以自行预计算C的一部分。
在计算C之前I是否更改无关紧要,ArrayFire持续追踪输入源头,而你将总是得到正确答案。每当你需要C的值,它都将自动进行运算。由于对C的计算可以作为单个核进行批处理而不是把里面的每个式子都执行一遍,这种处理方式相对于把每一步都交给GPU处理一次来说节省了时间。ArrayFIre利用这些信息进一步优化更大图片的计算版本,否则一条一条执行操作将变得不可能。你能从其中得到的另一个优点是在你代码里运行计算了一个,你实际上永远不会使用的值时,ArrayFire可以直接跳过它。如果计算C所需要的内存开始不足或者计算过程开始变得极端复杂,ArrayFire也可以自行预计算C的一部分。
4.索引
ArrayFire提供了几种灵活高效的方法,用于将下标索引进数组。和C/C++、Python以及Fortran相同,Array Fire的下标也是从0开始的,即A(0)是第一个元素。索引功能可以通过以下方法的组合实现: ·整型标量 ·seq 表示线性序列 ·end 表示维度的最后一个元素 ·span 代表整个维度 ·row(i)或col(i)指定单行或单列 ·rows(first,last)或cols(first,last)指定行或列的跨度。
下标阵列索引举例: array A = randu(3,3); array a1 = A(0); //首元素 array a2 = A(0,1); //首行第二列元素
A(end); //最后一个元素 A(-1); //也表示最后一个元素 A(end-1); //倒数第二个元素
A(1,span); //第二行 A.row(end); //最后一行 A.cols(1,end); //除了第一列的全部
float b_host[] = {0,1,2,3,4,5,6,7,8,9}; array b(b_host,10,dim4(1,10)); b(seq(3)); //{0,1,2} b(seq(1,7)); //{1,2,3,4,5,6,7} b(seq(1,2,7)); //{1,3,4,7} b(seq(0,2,end)); //{0,2,4,6,8}
在考虑性能时,数组索引很重要。因为内存的移动与重排操作代价昂贵,很容易就会让对下标的索引操作吃掉你从其他地方利用快速运算获得的加速。与我们需要尽量避免利用下标访问标量值相反,下标可以表示整个向量或元素矩阵。数据是被按列以主顺序存储(与Fortran相同),因此我们建议以连续的跨度按列索引,例如调用一整列A(span,a),而不是分散访问,例如调用那些跳过元素之间内存的行A(2,span)。你可以在网络上找到更多例子。
5.图形
除了通用型计算之外,GPU也是最快最重要的图像处理器。基于这一事实,ArrayFire附带了免费的和用于商业用途的软件包。ArrayFire比较独特的一点是,他的图形引擎是在考虑了GPGPU的基础计算的情况下从头开始设计的:所有的原语都是从卡上的内存里提取。因此,所有的计算与可视化处理都由GPU处理,省去了在主机CPU与设备之间内存转换的步骤。让GPU去做那些他擅长的工作,比如并行数据处理和图像输出,而CPU则负责一系列计算和图像后端的定位。
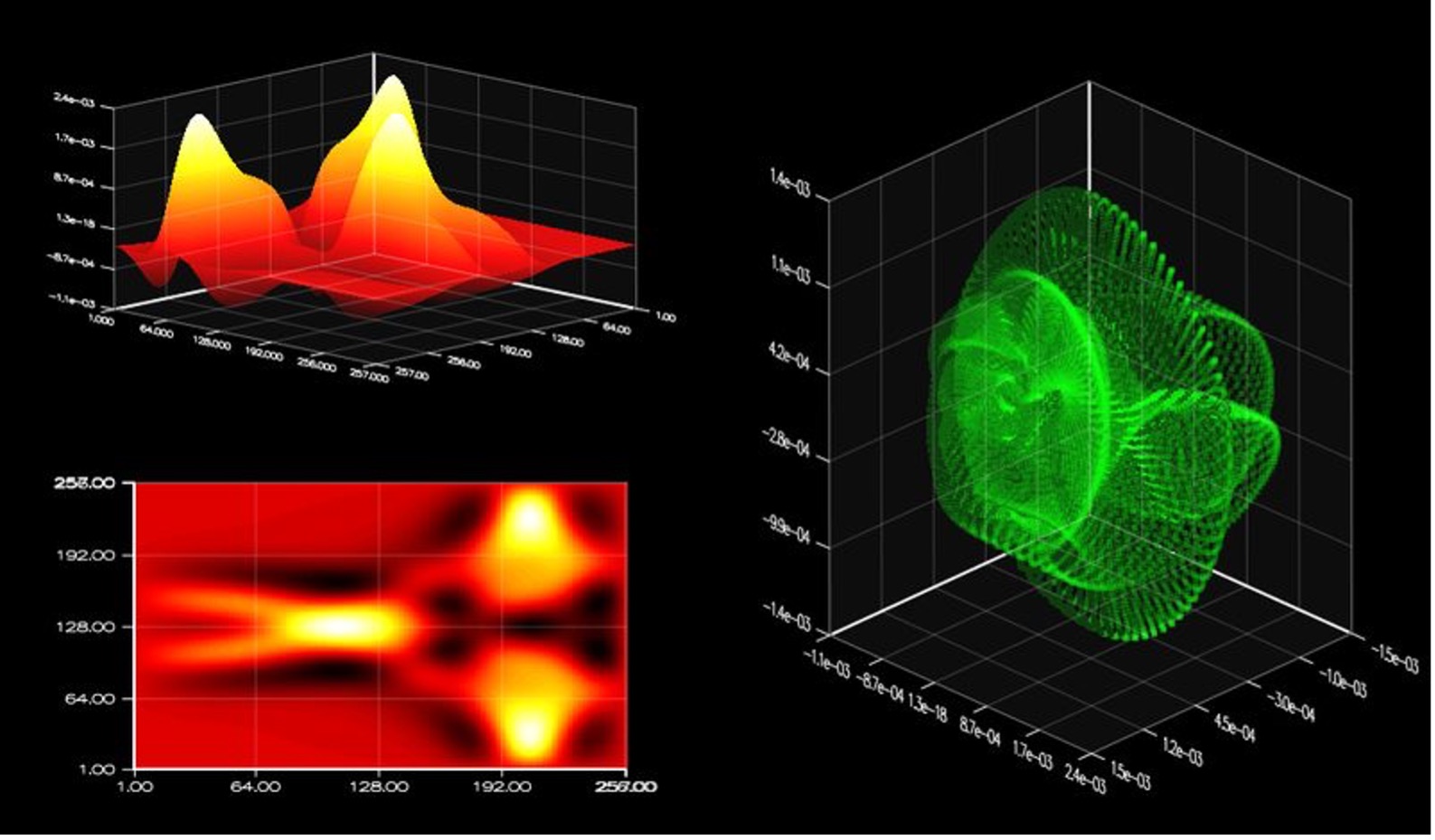 图3 潜水模拟中场景的各个子视图。
图3 潜水模拟中场景的各个子视图。
图像包包含了几种基础绘图原语,其中有: ·2D与3D线性绘图 ·立体渲染 ·用于比较分析的叠加图 ·图像可视化 ·其他还有很多
图像后端的工作应该简单一些,这样你才能集中精力解决问题,而不是把精力花在OpenGL或多线程实现等这些问题上。比如要画出图三所示的图像,只需要以下几条简单的C++代码: subfigure(2,2,1); plot3d(A); subfigure(2,2,3); imgplot(A); subfigure(2,1,2); points(dx,dy,dz);
6.GFOR
ArrayFire提供仅用于GPU的并行数据循环关键词:gfor。在代码中用gfor代替标准for 循环对批进程数据做并行数据处理。比如,如果我们使用for循环计算几个矩阵连续相乘需要以下代码:
for(int I = 0; i<2 ;i++){ C(span,span,i)=A(span,span,i)*B; }
同样的三个矩阵相乘的运算,使用gfor可以一次完成而不是三次。
gfor(array i,2){ C(span,span,i)=A(span,span,i)*B; }
与前一个循环连续计算了每个矩阵乘法运算不同,后一个循环一次性完成了所有矩阵乘法运算。与之相同的,gfor可以直接用于其他类似的麻烦的并行代码。一个考虑gfor的好方法是将它视为一个语法糖(syntactic suger):gfor提供一个用于编写其他矢量算法的迭代风格。
7.多GPU互联
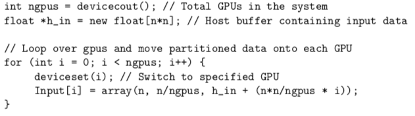
ArrayFire可以仅通过调用很少几条函数实现单GPU到多GPU互联的扩展配置。我们可以通过调用函数deviceset()来选择用来运算的GPU。此函数将给出允许调用ArrayFire的GPU的数量。为了同时在多个GPU上运行计算,我们将输入数据进行分块(如果必要)并将数据块分发给每个GPU。通过在循环中调用deciceset()函数来选择系统中的GPU并创建array对象可以实现上述目的。
然后是另一个循环,此循环调用快速傅立叶变换(FFT)函数对每个单独的数据块进行处理,所有运算过程都在系统中的各个GPU上并行运行。
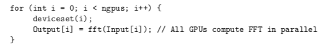
ArrayFire同样提供同步函数sync(),此函数可以阻止主线进程直到所有其他设备结束等待中的所有函数调用。为了将数据返回给主机,我们运行另一个循环将数据传送给主机上的缓冲区。

如上所述,利用Array Fire中非常友好的API可以非常简单的将单个GPU扩展到多GPU并行。
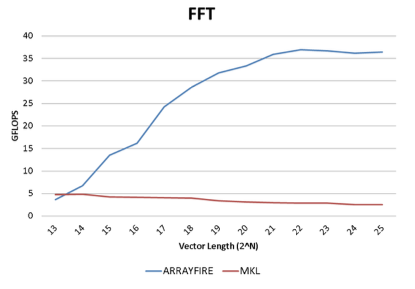
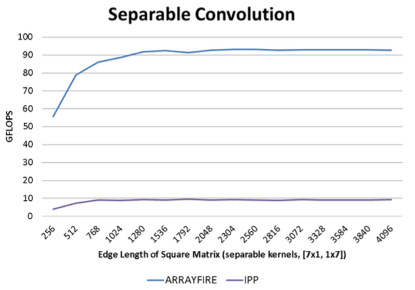
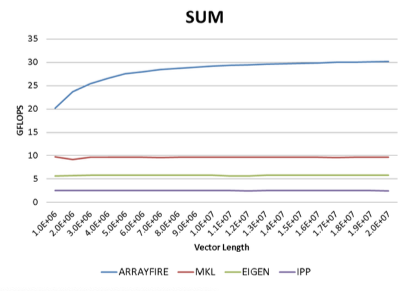
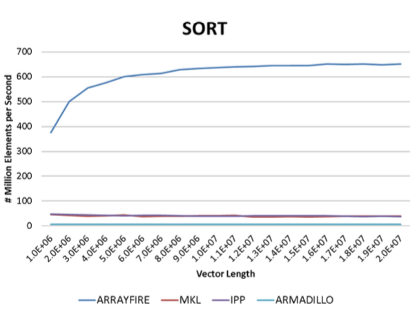
8.基准
ArrayFire很快。它利用GPU的并行数据处理能力获得比其他已知的所有商业用途或免费的库更强大的性能优势。我们对Array Fire支持的大量功能进行了样本基准测试。所有曲线都表示吞吐量,更高的曲线则表示更好的性能。所有测试均在以下标准下测试:
·硬件:Intel i7 920, Tesla C2050
·软件:ArrayFire 1.0, Intels MKL 10.3, Intels IPP 7.0, Eigen 3.0.
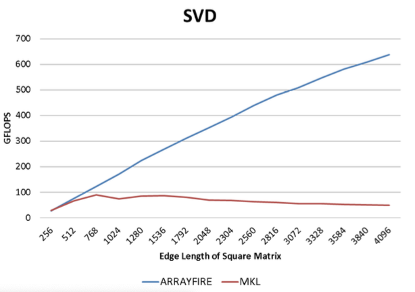
9.总结
新的软件工具与基于GPU的高性价比电脑的出现,为研究技术问题的科学家、工程师和分析师开创了一个新的时代。这篇文章描述的ArrayFire平台为那些正在寻找利用GPU计算能力的非计算机科学家提供了更加高效的选择。ArrayFire是一个快速GPU矩阵库,可以用C/C++ 、Fortran和Python语言编写通用GPU计算程序。本文展示了Array Fire的简单的API,并描述了为何它能快速构造GPU运算应用程序。ArrayFire实用性的关键元素是一边进行文字描述一边利用实际代码举例。最后,我们的测试结果展示了ArrayFire提供了一种快速的GPU计算方法。
参考文献
[1] AccelerEyes. Addr.: 800 W Peachtree St NW, Atlanta, GA 30308, USA. URL: http://www.accelereyes.com.
[2] Andy Webb: “MATLABs Racing Jacket”. Automated Trader, vol. 16, no. 1, pp 54–61. 2010.
[3] AccelerEyes: “Jacket v1.7.1: Getting Started Guide”. URL: http://www.accelereyes.com/services/documentation
[4] Mark Harris, “Optimizing CUDA”. SuperComputing 2007 Tutorial, Reno, NV, USA. November 2007.
[5] V.Volkov and J.W.Demmel,“Benchmarking GPUs to Tune Dense Linear Algebra”. SC ’08: Proceedings of the 2008 ACM/IEEE conference on Supercomputing, pp. 1-11, Austin, Texas, USA, 2008.
[6] Torben’s Corner. Available at the Wiki of AccelerEyes at: URL:http://www.accelereyes.com/wiki/index.php?title=Torben’s_Corner.
[7] nVidia, “CUDA programming guide 1.1,” Available at http://developer.download.nvidia.com/ compute/cuda/1_1/NVIDIA_CUDA_Programming_Guide_1.1.pdf
[8] nVidia, “CUDA CUBLAS Library 1.1,” Available at http://developer.download.nvidia.com/ compute/cuda/1_1/CUBLAS_Library_1.1.pdf
[9] nVidia, “CUDA CUFFT Library 1.1,” Available at http://developer.download.nvidia.com/compute/ cuda/1_1/CUFFT_Library_1.1.pdf
[10] nVidia, “PTX: Parallel Thread Execution ISA Version 1.1”, Available at http://www.nvidia.com/ object/cuda_develop.html
[11] Buck, I., Foley, T., Horn, D., Sugerman, J., Fatahalian, K., Houston, M., and Hanrahan, P., “Brook for GPUs: Stream computing on graphics hardware.” Transactions on Graphics and Visualization vol. 23, no. 3, Aug. 2004.
[12] Tarditi, D., Puri, S., and Oglesby, J.. Accelerator: Using data parallelism to program GPUs for General- Purpose uses. In International Conference on Architectural Support for Programming Languages and Op- erating Systems (2006)
[13] McCool, M. and Toit, S.D., Metaprogramming GPUs with Sh. A K Peters, 2004.
[14] Mark, W.R., Glanville, R.S., Akeley, K., and Kilgard, M.J. “Cg: A system for programming graphics in a c-like language.” Transactions on Graphics and Visualization vol. 22, no. 3, pp. 896-907, 2003
[15] Matt Pharr, ed., GPU Gems 2, Addison-Wesley, 2005.
[16] Hubert Nguyen, ed., GPU Gems 3, Addison-Wesley, 2007.
[17] D. G ̈oddeke, GPGPU Basic Math Tutorial, tech. report 300, Fachbereic Mathematik, Universitt Dortmund, 2005